The Inference Framework¶
The diagram below outlines the overall architecture of the inference framework.
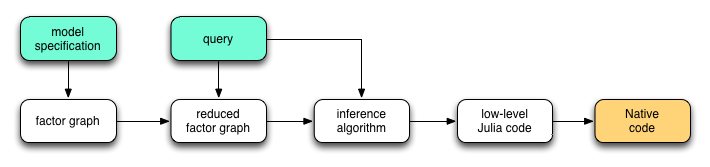
The entire process of generating inference codes from model and query specification consists of four stages:
The
@modelmacro will convert a model specification into a model class, of which the internal representation is a factor graph.The
@querymacro will reduce the factor graph based on the query. The reduction may involve following steps:- Simplify factors by absorbing known variables. For example, a second-order factor (i.e. a factor with two arguments)
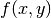 can be reduced to a first-order factor if the value of one variable (say
can be reduced to a first-order factor if the value of one variable (say 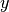 ) is given.
) is given. - Eliminate irrelevant variables and factors: variables and factors that do not influence the conditional distribution of the queried variables can be safely removed. For example, consider a joint distribution
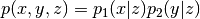 . When the value of is given, the variable is conditionally independent from
. When the value of is given, the variable is conditionally independent from 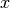 . Therefore, the variable can be ignored in the inference for .
. Therefore, the variable can be ignored in the inference for .
The macro
@queryalso generates a high-level description of the inference algorithm.- Simplify factors by absorbing known variables. For example, a second-order factor (i.e. a factor with two arguments)
An inference compiler will compiles the inference algorithm into low-level Julia codes, taking into account the computational architecture of the target platform (e.g. CPU cores, GPU, cluster, cloud, etc).
Finally, the Julia compiler will emit LLVM instructions, which will then be compiled into native codes by the LLVM compiler.
Here, we focus on the first two steps, that is, compilation of model and query specifications into inference algorithms.
Gaussian Mixture Model Revisited¶
To illustrate the procedure of model compilation, let’s revisit the Gaussian mixture model (GMM). Given a model specification, the @model macro creates a factor graph, which is a hyper-graph with factors connecting between variables. The following diagram is the factor graph that represents a GMM with two components.
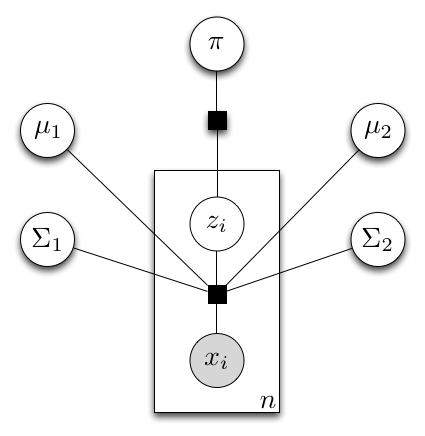
In this graph, each sample is associated with two factors, a mixture factor that connects between observed samples, components, and component indicator 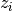 , and a factor that specifies the prior of each component indicator. These two factors were directly specified in the model specification. In the model learning query, the data
, and a factor that specifies the prior of each component indicator. These two factors were directly specified in the model specification. In the model learning query, the data x are given. Therefore the order of each mixture factor is reduced from 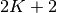 to
to 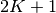 .
.
The most widely used learning algorithm for this purpose is Expectation Maximization, which comprises three updating steps, as outlined below.
Update the poterior probabilities of
conditioned on prior 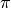 , component parameters
, component parameters 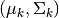 , and the corresponding observed sample
, and the corresponding observed sample 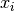 , as
, as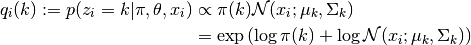
This can be interpreted as an integration of a message from the prior factor (that is,) and a message from the corresponding mixture factor (that is,
). Here,
Update the maximum likelihood estimation of
, as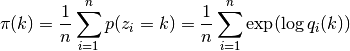
This can be interpreted as a computational process that combines messages from each of).
Update the maximum likelihood estimation of component parameters
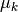 and
and 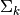 , as
, as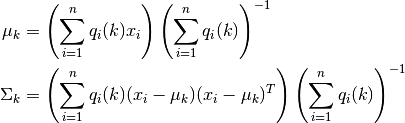
Again, this is also a specific way that combines messages from each of the mixture factors associated with them.
The analysis above shows that the E-M algorithm can be viewed as a message-passing scheme that iteratively update the states associated with each variable by exchanging messages between factors and variables. Actually, the message-passing scheme is a very general paradigm. Many widely used inference algorithms, including mean-field based variational inference, belief propagation, expectation propagation, Gibbs sampling, and Hamiltonian Monte Carlo, can be implemented as certain forms of message passing schemes.
Inference via Message Passing¶
Generally, a message passing procedure consists of several stages:
Initialize the states associated with each variable. Depending on the chosen algorithm, the states associated with a variable can be in differen forms. For example, for a discrete variable, its associated state can be a value (in Gibbs sampling or maximum-likelihood estimation), variational distribution (in variational inference), or a marginal distribution (in belief propagation or expectation propagation).
Iteratively invoke the following steps until convergence or other termination criteria are met.
- update the message from a factor to some of its incident variables (based on updated status of other incident variables).
- update variable states based on incoming messages.
Compute queried quantities based on variable states. For example, if a Gibbs sampling algorithm is used, the expectation of a variable can be approximated by the sample mean.
It is possible to generate such an inference procedure according to the structure of the factor graph. However, there remains several challenges to be addressed:
- Some intermediate quantities may be used in the computation of several different messages. For example,
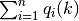 appears in multiple updating formulas for GMM. It is desirable to identify these quantities and avoid unnecessary re-computation of the same value.
appears in multiple updating formulas for GMM. It is desirable to identify these quantities and avoid unnecessary re-computation of the same value. - Each message depends on the states of several variables, while the states of a variable may depend on several messages. A message/variable state only needs to be updated when its depending values have changed. To identify whether a variable/message needs to be updated, a natural idea is to build a dependency graph, where each node corresponds to either a variable state or a message. By time-stamping each node, it is not difficult to see whether a node can be updated by looking at the time-stamps of each neighboring nodes.
- Updating steps can be scheduled in numerous ways. Poor scheduling may result in slow convergence. Therefore, deriving a reasonable schedule is also important to achieve high efficiency.